Note: the author of this paper has moved to liamquin at interlog dot com
The word is then looked up to see if it was in the common words file. If so, it is rejected and the next successfully read word will have the WPF_LASTWASCOMMON flag set. In addition, whenever the start of this word is more than one character beyond the start of the previous successfully read word - as in the case that a common word, or extra space or punctuation, was skipped - the next successfully read word will have the WPF_HASSTUFFBEFORE flag set, and the distance will be stored in the Separation byte shown in Table 3.
Common word look-up uses linear search in one of two sorted lists, depending on the first letter of the word. Using two lists doubled the speed of the code with very little change, but if more than 50 or so words are used, the common word search becomes a significant overhead; a future version of lq-text will address this.
After being accepted, the word is passed to the stemmer. Currently, the default compiled-in stemmer attempts to detect possessive forms, and to reduce plurals to the singular. For example, feet is stored as a match for foot, rather than in its own entry; there will be no entry for feet. When the stemmer decides a word was possessive, it removes the trailing apostrophe or 's, and sets the WPF_POSSESSIVE flag. When a plural is reduced to its singular, the WPF_WASPLURAL flag is set.
Other stemming strategies are possible. The most widespread is Porter's Algorithm, and this is discussed with examples in the references [Salt88], [Frak92]. Such an alternate stemmer can be specified in the configuration file. Porter's algorithm will conflate more terms, so that there are many fewer separate index entries. Since, however, the algorithm does not attempt etymological analysis, these conflations are often surprising.
The converted words are then mapped to a WID as described above, and stored in an in-memory symbol table. Whenever the symbol table is full, and also at the end of an index run, the pending entries are added to the index, appending to the linked-list chains in the data file. The ability to add to the data for an individual word at any time means that an lq-text index can be added to at any time.
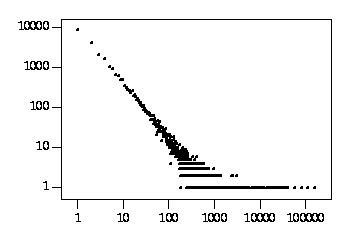
The figure shows the
vocabulary distribution graph
for the combined index to the King James Bible, the
New International Version, and the complete works
of Shakespeare, a total of some 15 megabytes of text.
The New International Version of the Bible is in modern English,
and the other two are in 16th Century English.
It can be seen from the graph that
a few words account for almost all of the data,
and almost all words occur fewer than ten times.
The frequency f of the nth most frequent word is usually given by
Zipf's Law,
f = k(n + m)s
where k, m and s are nearly constant for a given collection of documents [Zipf49], [Mand53]. As a result, the optimisation whereby lq-text packs the first half dozen or so matches into the end of the fixed-size record for that word, filling the space reserved for storing long words, is a significant saving. On the other hand, the delta encoding gives spectacular savings for those few very frequent words: `the' occurs over 50,000 times in the SunOS manual pages, for example; the delta coding and the compressed numbers reduce the storage requirements from 11 to just over three bytes, a saving of almost 400,000 bytes in the index. Although Zipf's Law is widely quoted in the literature, the author is not aware of any other text retrieval packages that are described as optimising for it in this way.lqword -A | awk '{print $6}' | sort -n
was sufficient to generate data for a grap(1) plot of
word frequencies shown in the graph, above.
It is also possible to pipe the output of lqword into the retrieval programs discussed below in order to see every occurrence of a given word.
The client then calls LQT_MakeMatches(), which uses the data structure to return a set of matches. A better than linear time algorithm, no worse than O(total number of matches) is used; this is outlined in Algorithm 1, and the data structure used is illustrated in Figure 2.
[1] For each word in the first phrase {
[2] for each subsequent word in the phrase {
[3] is there a word that continues the match rightward? {
Starting at current pointer, scan forward for
a match in the same file;
Continue, looking for a match in the same block,
or in an adjacent block;
Check that the flags are compatible
If no match found, go back to step [1]
Else, if we're looking at the last word {
Accept the match
} else {
continue at step [2]
}
}
}
}
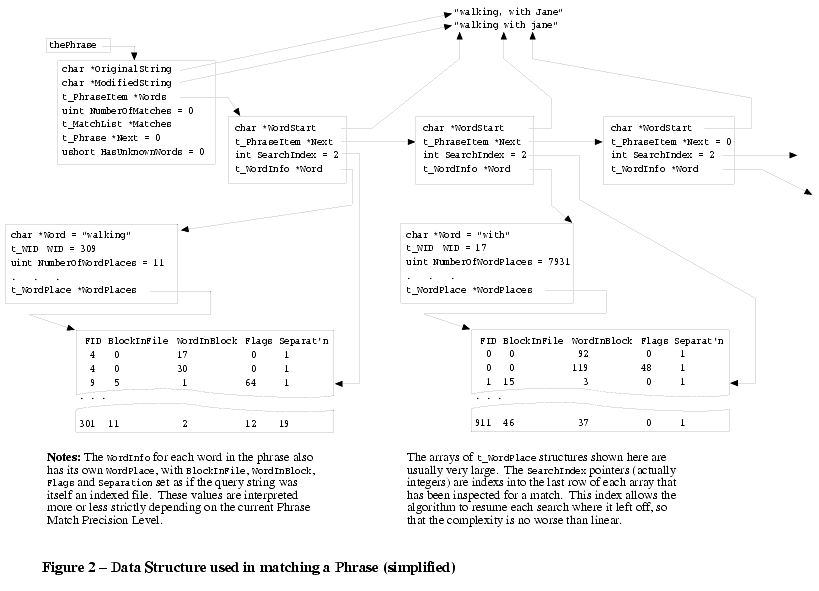
This appears O(nw) at first sight, if there are w words in the phrase each with w matches, but the search at step [3] resumes at the `current' pointer, the high-water mark reached for the previous word at step [1]. As a result, each match is inspected no more than once. For a phrase of three or more words, the matches for the last word of the phrase are inspected only if there is at least one two-word prefix of the phrase. As a consequence, the algorithm performs in better than linear time with respect to the total number of matches of all of the words in the phrase. In addition, although the data structure in the figure is shown with all of the information for each word already read from disk, the algorithm is actually somewhat lazy, and fetches only on demand.
Statistical ranking - for example, where documents containing the given phrases many times rank more highly than those containing the phrases only once - is also planned work. See [Salt88]. Statistical ranking and document similarity, where a whole document is taken as a query, should also take document length into account, however; this is an active research area [Harm93].
The initial implementation of lqrank used sed and fgrep. This was improved by Tom Christiansen to use perl, and then coped with larger results sets (fgrep has a limit), but was slower.
The current version is written in C. For ease of use, lqrank can take phrases directly, as well as lists of matches and files containing lists of matches.
The algorithms in lqrank are not unusual; the interested reader is referred to the actual code.
[1] Number of words in query phrase
[2] Block within file
[3] Word number within block
[4] File Number
[5] File Name and Location
(Items [4] and [5] are optional, but at least one must be present.)
In itself, this is often useful information, but the programs described below - lqkwic and lqshow - can return the corresponding parts of the actual documents.
See the Appendix for sample lqkwic output.
The original purpose of lq was to demonstrate the use
of the various lq-text programs, but lq is widely
used in its own right.
A brief example of using lq to generate a keyword in context
listing from the netnews news.answers newsgroup
is shown in the Appendix.