
At the time of writing this paper, Liam Quin was a Senior Technical Consultant in the Professional Services Division at SoftQuad Inc., where he has worked since 1990. His interests include typography and design, antiquarian books and old dictionaries, and the all usual SGML stuff. He is currently (1998) Director of Development at GroveWare Inc. |
Liam Quin,
Senior Technical Consultant
SoftQuad Inc.
Toronto, Ont
Canada M4R 1K8
Keywords: ambiguity, semeiotics, SGML, DTD
Note The author has since moved to GroveWare.
This paper was presented by the author at the GCA SGML 96 Conference in Boston, December 1996.
Abstract
1. Prescriptive and Descriptive DTDs
1.1 Prescriptive DTDs
1.2 Descriptive DTDs
1.3 A Quick Comparison
2. What is Ambiguity?
2.1 Understanding Handwriting and Speech
2.2 Ghosts in the Mist
2.3 Unauthorised Interpretations
2.4 Troubled Relationships
3. Why Represent Ambiguity?
3.1 Preserve Editorial Authority
3.2 Incomplete Document Analysis
4. Explicit Representation of Ambiguity
4.1 Discordant Elements
4.2 Marked Sections
4.3 External Markup with HyTime Links
4.4 OMITTAG and multiple DTDs
4.5 SUBDOC and CONCUR
4.6 Attributes
4.6.1 name groups
4.6.2 unrestricted CDATA attributes
4.6.3 Summary of attribute approaches
5. Relationships and Ambiguity
6. Suggestive Moves
6.1 Structural Ambiguity and Relationships
6.2 Incomplete Analysis
7. Conclusion
8. Acknowledgements
Bibliography
The SGML literature divides DTDs into two types: those that describe existing information structures and those that prescribe a fixed set of structures. A purely prescriptive approach has been in vogue for several years; however, the descriptive approach has much to offer. It is suggested that many DTDs should in fact fall somewhere between the two extremes, and could be termed suggestive. In a Suggestive DTD, certain structures are fixed, others are flexible, and still others are configured through the simple use of attributes to permit previously unexpected values. Relationships are explicitly marked where they cannot be derived.
These two types of DTD are in widespread use today; the following descriptions are intended to be illustrative and explanatory, and not definitive.
A prescriptive DTD may be designed to create new material or to mark up existing material, and has the chief characteristic that it prescribes a set of rules which all matching documents must follow. If a document contains a structure that cannot be described by the DTD, either the document analysis was at fault (in which case the DTD must be re-evaluated) or, most likely, the document must be changed to fit the DTD.
A prescriptive DTD can only be used by people who have sufficient editorial authority so that they can mandate the structure of documents, even where doing so may in subtle ways change the meaning of the documents.
This is, of course, an extreme characterisation of the prescriptive approach. In practice, many compromises are made, and the discussion of ambiguities in this paper could be considered to fall into that category.
Examples of prescriptive DTDs in widespread use may be said to include DOCBOOK, ISO12083, PCIS and the various CALS DTDs. Note that extensive document analysis was carried out in each of these cases, so that the structures they mandate are in fact very likely to be the same as those found in almost all actual documents in their respective domains. Once those structures were more or less fixed, however, the intent is that documents adhere to their rules.
A descriptive DTD is used to create an electronic version of material that already exists in a non-SGML format. The chief characteristic of such a DTD is that it attempts to describe structures that exist, rather than to force any particular structure. If something should occur in a document that a descriptive DTD does not permit, it is the DTD that must be modified. Of course, a descriptive DTD may also be used to create new documents.
Examples of descriptive DTDs in widespread use are a little harder to find, as this way of using SGML has until recently largely been confined to academic humanities computing, with the Text Encoding Initiative's modular DTD set (P3 is the latest version at the time of writing) being by far the most widely used.
|
Figure 1.
|
The two approaches can be understood most easily by considering a concrete example. Consider a glossary, which consists of terms to be defined followed by their definition. An excerpt from an 18th Century glossary [Hearne1810] is reproduced in Figure 1. In this example, notice that the editor has inserted a poem into the glossary; the next page (not shown) also contains a piece of correspondence that the author received, set as a block quote. This is a little unconventional, and most glossary DTDs do not allow letters or poems between or within entries. A prescriptive DTD would force the author to delete these items from the glossary, perhaps moving them into the main body of the text in order to keep the glossary clear.
The editor of this glossary, Thomas Hearne, sadly passed away on the 10th of June, 1735, and is unfortunately not available to revise his work. In transcribing this document, the DTD must be revised to permit the usage that we see.
Which approach is suitable depends on whether the people using SGML have editorial authority over the documents, or can otherwise exercise some right or privilege to have documents changed where necessary so that they conform to the DTD. When SGML is used for an in-house project such as a technical manual or an internal database, such authority is usually present, and the prescriptive approach is generally taken. Since the DTD quickly becomes very stable, software that processes the SGML can be written in a DTD-specific manner, which is often cheaper than more general code. When external agents are involved, such as contracted authors or conversion houses, the issues may not be so clear-cut. And of course, if you are transcribing existing material, you have no choice but to accept it for what it is.
Chambers' English Dictionary [Chambers1988] says that something is `ambiguous' if it admits of more than one meaning; Nathan Bailey defined Ambiguousness as a double Meaning, Obscurity in Words. [Bailey1736]
This much is clear. But what are we speaking of that is so ambiguous? When one uses SGML, one might be marking up existing documents, or creating new ones. In the former case, the original material might be obscure in some way. In either case, the SGML markup may at the same time remove some forms of ambiguity and yet actually create other obscurities. Hence, we might see ambiguity in the source information, in the markup, or in the way in which the markup is applied.
In all cases, an overriding concern must be that any process, whether human or not, that either introduces or removes ambiguity, and perhaps thereby changes the meaning of the encoded information, must have the necessary editorial authority to make those changes. Some examples of this will be discussed later.
The following sections describe some forms of ambiguity and obscurity, and discuss briefly when it may be important to clarify them explicitly or to preserve them.
Anyone who has ever received a hand written letter has undoubtedly found occasions in which a certain word could be read in more than one way, and has had no clear way to choose between the variant readings. It might even be in some cases that the writer intended these multiple readings. It is clear that a typed transcription of such a letter may need to preserve the variant readings.
In a similar vein, a transcription of a spoken conversation may have to indicate that the transcriber could not distinguish or understand a particular word or phrase.
Figure 2. The typewritten example is used by permission of Ontario Hydro. |
In a printed document, one will normally be able to be read what is written. That is, there is usually little room for doubt in the actual letter forms. It is often difficult, however, to interpret changes in formatting. For example, a single word or phrase may be italicised for no apparent reason. A heading might apply to a list that follows it , or to both the list and several following paragraphs. A list might be within or outside a paragraph.
Consider the text shown in Figure 2. It is not clear whether the words `Permissible Spray Heights' before the start of the list form a list heading, or whether the list should actually be within the same paragraph as that sentence fragment. In this case, the meaning is probably not affected significantly, but the resulting structures are certainly different; in a large conversion project it would be difficult to achieve consistent markup of such material. In this instance, the material was typed many years ago, and the original staff are not available to answer questions about the information. Of course, in practice it is usually possible to come to an agreement on a case by case basis, but for even only a few thousand documents that can quickly grow tedious.
|
Figure 3. Bailey's 1736 Dictionary: Boyish |
Markup implies certainty. If an italicised word is surrounded with KEYWORD tags, there is an implication that the word is italicised precisely because it is a keyword. But there are many other possible uses of italic, such as for emphasis (speak the word a little more loudly), to indicate that it is a foreign term, or even for pure decoration.
Anyone coming later to inspect the marked up document will surely assume that the markup is correct; unless they see good reason to doubt it, they will believe the italicised word to be a keyword. In this case, it probably does no damage if in fact it is in italic because a word processor operator pressed Control-I instead of Control-B by mistake. But what if the element had been called SEXIST, and had been used by a team of editors to indicate passages they believed to be discriminatory?
Figure 3 is from Baileys' 1736 dictionary: you can see that the first letter of the word `Boy' is in small caps. One might assume that this is because it's related to the headword, but in fact most of the words starting with B on this page (and the rest of the forme) are treated in the same way, and this is done nowhere else in the dictionary. It seems more likely, then, that they ran out of capital B type, and had to substitute. Or maybe it was because one of the compositors did things a little differently, and no-one noticed until it was too late. The subsequent entry shown in the same figure, for Bp, contains an italic B instead of a small-caps one. In any case, it would be a mistake to mark this up as using small caps with no other comment, as people using only the electronic text would not be able to determine why such small caps only appeared in one place, and might assume a markup error. We would have introduced an ambiguity, as subsequent readers of the text would not know whether the irregularity (or error, if you will) was present in the text or introduced by the transcriber.
Perhaps few people are concerned with this level of detail in marking up old texts, but the markup of irregular constructs is a real issue when modern texts are converted into SGML, for instance, or when a DTD such as DOCBOOK is distributed to be used by other people.
Figure 4. Bailey's 1736 Dictionary: Ascii |
Figure 4 shows Bailey's 1736 definition for ASCII; the etymology is given, in which one can clearly read the word `and' to indicate a followed-by relationship. In marking this up in SGML, one might use a `followed by' element to represent this, for example. This approach is discussed further under Relationships and Ambiguity below. But it might well happen that the relationship indicated in the etymology is itself ambiguous.
|
Figure 5. Bailey's 1736 Dictionary: Brandy and Cashire |
In the etymology for Brandy, does brande vin does not mean to burn. Or, again, which words derive from cassare in the definition for Cashire?
Where relationships between parts of a document are intended, an author working in SGML can of course mark them explicitly. In some cases (as in Pinnacles PCIS, for example) there is great value in doing so, and authors will willingly comply. In other cases, the authors may not wish to do this, or may not be working in SGML. Nathan Bailey himself did not even use a digital computer. As a result, there are many cases in which such relationships must be marked up either by hand or by automatic conversion, and where there may be a great danger of changing the status of the certainty of the relationship in so doing.
In some environments, it may seem that ambiguity is a thing detestable, to be eliminated wherever it is practical to do so. But it is not possible to eliminate ambiguity or uncertain readings without changing the meaning of the text so altered. In some environments, such as political manifestos, it may be argued that ambiguity is actually an intended goal, but that is not within the scope of this paper.
As mentioned above, if you do not have authority to change the meaning of the document you are working with, and you cannot ask the author or anyone else with such authority to make a decision, you may need to retain the ambiguity.
Although the meaning may be clear, the difficulty may be in which element name to use! Fairly general markup may later be changed to more specific elements after a number of actual instances have been analysed, as long as sufficient information is retained. The use of attributes to preserve information about uncertainty rather than ambiguity per se is discussed below. Note the use of italics to mark a foreign phrase in this very paragraph; the DTD used does not have a special element for this, and the reason for using italics was not captured, making it impossible to search the conference proceedings for foreign phrases.
Once we have accepted the desirability of representing ambiguity and obscurity in SGML, a concrete representation must be chosen. There are several possible approaches which will each be described in turn.
There is a dark
Inscrutable workmanship that reconciles
Discordant elements.
(Wordsworth, The Prelude, I. 341)
One approach to representing the possibility of multiple or uncertain readings of a text is to use a separate element for each possible reading.
For example, one might use markup such as this:
<obscure>
<variants>
<italics>hors<italics>
<foreign>hors</foreign>
</variants>
</obscure>
Most people would consider that this is an excessive amount of markup compared to the same approach using attributes:
<italic reason="foreign(FR)">hors</italic>
The main advantage of using elements is that they can themselves hold attributes; for example, one could use
<foreign language="FR">hors</foreign>
which is less clumsy than the (FR) approach illustrated in the italic example.
This is similar to the CALS Effectivity work, and also to the use of marked sections with associated parameter entities. These mechanisms were not designed to represent ambiguity; they are instead better suited to representing multiple documents or versions of documents that happen to be stored together. The situation under discussion is where a single document might have multiple concurrent readings.
In practice, a pragmatic approach seems to be a combination of elements and attributes, and this is explored further in the Suggestions section below. Note that if the DTD does not support an element to hold textual variations, the marked section approach described in the next section can sometimes be used.
In the common case where only a single variant needs to be recorded, as for example, italic versus foreign, the attribute approach is more convenient.
It is already common to use marked sections to combine multiple versions of a document; parameter entities are used to control which of any number of possible readings of a document is current. But this approach does not encode the ambiguity itself: it permits the multiple readings to be placed side by side, but forces a choice.
As noted above, this approach is very similar to the Effectivity and Element approach. Since marked sections cannot be assigned attributes, it is less powerful than using elements. Application support is stronger for marked sections, though, than for controlling visibility of element content, so the most effective approach is to use both elements and marked sections. For this to be manageable, editing applications need to be scripted or modified to handle what can otherwise be tedious and error-prone interdependencies.
Suppose that a document is marked up in a minimal fashion, so that only those elements which may be identified with a great deal of certainty are present. This may include paragraphs, for example, but might omit keyword or Procedure/Step markup. All of the text is present, but sometimes what might have been element boundaries are entirely unmarked.
Now suppose further a second document, this time containing nothing but annotated HyTime links pointing into that first minimal SGML structure. The annotations say, for example, here is a quotation, or here is a foreign word, or here is a phrase that indicates political bias.
An application could, in principle, combine these two SGML documents in such a way as to attach stylistic presentation to the text based on the HyTime markup. The skeletal structure in the that document would serve no other purpose than to facilitate the creation of the HyTime links and to simplify editing or creation of the text.
Unfortunately, no such application exists (as far as the author is aware). SoftQuad Panorama Pro and SoftQuad Explorer can interpret HyTime links and either highlight the resulting spans in the target document or place icons at the start, and this may be sufficient for some purposes.
This approach is not, however, amenable to the ongoing editing of documents, since as the text is edited, HyTime DATALOC links will begin to point to the wrong place.
The approach of using external links does mean that multiple sets of markup could be kept, and maybe compared or superimposed.
This technique was pioneered by David Megginson when he was a graduate student at the University of Toronto, where he used it to represent multiple readings of Old English poetry. The strategy is to arrange that the same instance can be interpreted in multiple ways merely by changing the DTD. It relies on the idea that OMITTAG can be specified in such a way that what in one DTD is an empty element is in another DTD a container. Unfortunately, most commercial SGML editors expand all tags when they save documents, so that this technique is not robust.
The representation of variant readings as multiple concurrent documents, each with its own DTDs, using the SGML CONCUR feature, is beyond the scope of this paper, but is left as an exercise for the hyperactive reader. Note that this sort of approach uses features of SGML that are not widely implemented.
It would also be possible to create multiple copies of the text, each marked up distinctly, and to use SUBDOC entities to refer to them, but this feature is also not generally supported; worse, the duplication of the text leads to difficulties in updating documents. In any case, one usually has to decide upon a single `master' reading for the purpose of printing or preparing an online edition, unless one is actually making a critical edition comparing the differences.
These two approaches are again similar in spirit perhaps to the CALS Effectivity work, and also to the use of marked sections with associated parameter entities. These mechanisms are best used for representing multiple documents or versions of documents that happen to be stored together, rather than documents containing many independent variations.
The approaches mentioned so far have all been explicit in that they encode all the variant readings. This is a lot of work, and can generate unwieldy documents that are hard to manage and hard to display.
In a Suggestive DTD, the document is encoded as if for a prescriptive markup, but with a small amount of extra tagging to suggest places where ambiguities exist, or where the document is not yet fully `frozen'.
First, consider again the hors example as it might be marked up with attributes:
<italic reason="foreign">hors</italic>
It is very common to use name groups such as
<!AttList Italic
Reason (foreign|emphasis) #REQUIRED
>
But if unexpected markup may occur, it may be better to use an approach by which an author can suggest a new value:
<!AttList Italic
Reason (Foreign|Stressed|Other) #REQUIRED
If.Other CDATA #IMPLIED
>
The intent is that the If.Other attribute is only used when Reason is set to Other. There is no way to enforce the idea that the if.other attribute should only be used when Role is Other except through training and Mutual Agreement. For a small user community, there is little doubt that this can be effective. After a body of material is collected, if it should happen that a great many occurrences of Reason=DefinedTerm occur, the value can be moved into the main name group, and the instances all changed with a batch search and replace, using Balise or Omnimark for example.
Another approach to the same idea of suggesting uncertainty is to use an element corresponding to each token in the name group shown above, and also have an element that is used to encode other face changes:
<!Element Stress . . .
<!Element Foreign . . .
<!Element Face . . .
<!AttList Stress
Reason CDATA #REQUIRED
Typeface CDATA #IMPLIED --* default to italic *--
>
The two approaches shown here are in fact very similar, and it may well be that one can migrate individual elements between them as convenience and intellectual elegance suggest.
Most of the discussion so far has been centred on identifying and representing ambiguity. However, there are other cases where one may wish to reduce ambiguity, and use an external method such as a comment or documentation to indicate that this has been done.
Consider again the Bailey's etymology for Cashire given in Figure 5. This could be marked up simply like this:
<i>casser</i>, F. <i>casser<i>, Sp. and It. of <i>cassare<i>, L.
However, this fails to capture the relationships that one might perceive between the various terms. A structure might be created as shown in Figure 6.
Figure 6.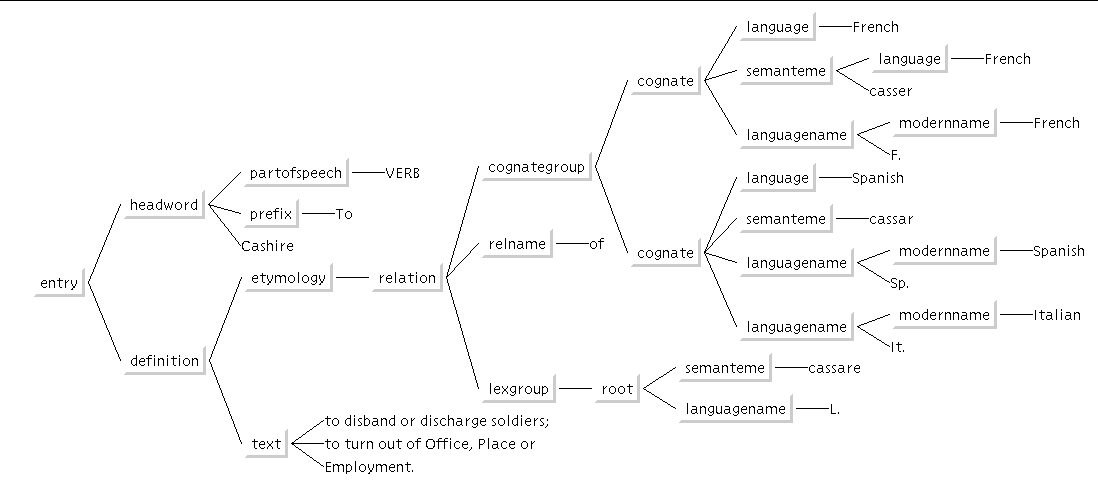 |
This figure captures relationships such as derived from explicitly. One danger is that it is often difficult to interpret an 18th Century printed book correctly with any great degree of confidence. The same technique, however, does not have any such difficulty where the authors may be consulted, as for example in the creation of PCIS semiconductor data sheets.
The Bailey's Dictionary etymology example might be marked up as follows:
<!DOCTYPE Dictionary PUBLIC "-//LIAM QUIN/DTD BAILEYS 1736//EN">
<ENTRY>
<HeadWord PartOfSpeech="VERB" Prefix="To ">
Cashire
</HeadWord>
<Definition>
<Etymology>
<Relation>
<CognateGroup>
<Cognate Language="French">
<Semanteme Language="French">
casser
</Semanteme>
<LanguageName ModernName="French">
F.
</LanguageName>
</Cognate>
<Cognate Language="Spanish">
<Semanteme>
cassar
</Semanteme>
<LanguageName ModernName="Spanish">
Sp.
</LanguageName>
<LanguageName ModernName="Italian">
It.
</LanguageName>
</Cognate>
</CognateGroup>
<RelName>
of
</RelName>
<LexGroup>
<Root>
<Semanteme>
cassare
</Semanteme>
<LanguageName>
L.
</LanguageName>
</Root>
</LexGroup>
</Relation>
</Etymology>
<Text>
to disband or discharge soldiers;
to turn out of Office, Place or Employment.
</Text>
</Definition>
</ENTRY>
This example does not include white space and punctuation; a DIRT element could be used for such items; the resulting mess is left as an exercise for the interested reader to construct. One solution may be seen on the World Wide Web; see reference [Quin1995]. The example also does not take into account the possibility of misreading the text, of ambiguity in the text, or of representing textual errors. It has, in fact, reduced the information about the status of the text at the same time as increasing the structural information that is encoded.
It is questionable whether such a highly structured level of markup is in fact appropriate for a text where neither editorial nor authorial opinion may be consulted. The author of this paper would welcome comments on this issue. However that may be, in cases where the meaning of the document can be ascertained, the explicit markup of relationships is clearly removing many possible ambiguities. It can also enable further reasoning based on the relationships that are now easily referred to in searches, database queries, formatting style sheets or other transformations. The tree view given in the figure was generated from such markup.
One could, of course, add an attribute to the relation element to indicate whether the relationship was explicit in the document or has been inferred by the person marking it up.
Markup of relationships goes one step further than the content tagging of individual elements of text that is often combined with generic structural elements such as chapter or title. It is most obviously of use in complex projects such as an encyclop�dia or dictionary, but even in business documents one might want to record the relative roles of two people, such as a project archivist working for a manager.
A number of approaches to various closely related issues have been discussed; this section gives some practical suggestions for incorporating some of the approaches into SGML DTDs for modern applications.
This is perhaps the hardest kind of ambiguity to deal with in practice, despite being the easiest to explain. Where a title has a relationship to a number of following paragraphs, that relationship is usually expressed by making sure that there is a single element containing the title and the text to which it refers. For example, the DIV element is available for this purpose in HTML.
Wherever adjacency of text is used to represent a relationship, a DTD designer should consider representing that relationship with an element, and making it explicit.
This may actually be reducing ambiguity in the document. If the relationship is unclear, but it is clear that there is a relationship, consider using an attribute to specify the most likely relationship, and making the element name neutral. If it later transpires that the same relationship is used many times, and the interpretation becomes certain (or nearly so), it may become appropriate to perform a global search and replace operation to rename all of the relationship elements with that attribute value to be elements in their own right.
In the more difficult case of uncertainty about the scope of a heading, or other structural obscurity, it might be appropriate to use an attribute to indicate the uncertainty; anyone needing more precise information would need to consult the original document.
It often happens that a DTD allows a fixed set of elements for content-tagged markup, but that a need arises for an extra element. There is always a strong temptation to extend the DTD, but this should be resisted, as it can quickly lead to an over-complex structure that is difficult to maintain.
If you give an attribute a name group for possible values, consider adding an if.other attribute:
<!AttList Person
Role (clergy|police|dancer|wheelwright|unemployed|Other) #REQUIRED
if.other CDATA #IMPLIED
>
As in the structural example given earlier, if it should happen that there are a great number of identical uses, such as if.other = "fishmonger", the Fishmonger role could be moved into the model group, and a global search and replace performed to change the instances appropriately.
It is perhaps unfortunate that it is not possible to include #CDATA in a name group to mean that any value may be used, but also to imply that the other values given in the name group are to be preferred.
Ambiguity can cause problems in itself; worse,when documents are encoded unambiguously, information can be lost.
Even when new documents are being created, it may be very useful for authors to be able to make suggestions in their markup without being overly explicit.
Allowing markup to stabilise over time may reduce the cost and difficulty associated with starting a new SGML project.
Another approach to ambiguity is to eliminate it consciously, by making editorial decisions and using unambiguous markup. In practice, a combination of these methods may be most effective.
Considering the effect of markup on the interpretation of data is a small but nonetheless essential part of data analysis and DTD design. A number of practical suggestions have been given for addressing these issues.
Finally, it is perhaps worth pointing out that there is another kind of ambiguity that has not been discussed: deliberate obscurity, where an author actually intends that multiple readings be possible, perhaps in order to mislead an unwary reader. Such usage is deprecated.
The author wishes to thank SoftQuad Inc., and particularly Roberto Drassinower, for making time available, and David Slocombe for reviewing an early draft. The typewritten example is used by permission of Ontario Hydro. Debbie and Tommie, and also Michael Sperberg-McQueen, showed interest in the subject and provided encouragement. Stan Bevington and Chris at Coach House Press scanned all of the images except the Glossary example.