Note: the author of this paper has moved to liamquin at interlog dot com
| This paper describes lq-text, an inverted index text retrieval package written by the author. Inverted index text retrieval provides a fast and effective way of searching large amounts of text. This is implemented by making an index to all of the natural-language words that occur in the text. The actual text remains unaltered in place, or, if desired, can be compressed or archived; the index allows rapid searching even if the data files have been altogether removed. | ||
| The design and implementation of lq-text are discussed, and performance measurements are given for comparison with other text searching programs such as grep and agrep. The functionality provided is compared briefly with other packages such as glimpse and zbrowser. | ||
| The lq-text package is available in source form, has been successfully integrated into a number of other systems and products, and is in use at over 100 sites. |
The main reason for developing lq-text was to provide an inexpensive (or free) package that could index and search fairly large corpora, and that would integrate well with other Unix tools.
There are already a number of commercial text retrieval packages available for the Unix operating system. However, the prices for these packages range from Cdn$30,000 to well over $150,000. In addition, the packages are not always available on any given platform. A few packages were freely available for Unix at the time the project was started, but generally had severe limitations, as mentioned below.
Some of the freely available tools used grep to search the data. While lq-text is O(n) on the number of matches, irrespective of the size of the data, grep is O(n) on the size of the data, irrespective of the number of matches. This limits the maximum speed of the system, and searching for an unusual term in a large database of several gigabytes would be infeasible with grep. Other packages had limits such as 32767 files indexed or 65535 bytes per file. Tools available on, or ported from, MS/DOS were particularly likely to suffer from this malaise.
Unix has always been a productive text processing environment, and one would want to be able to use any new text processing tools in combination with other tools in that environment.
The main goals of any text retrieval package were outlined briefly in the introduction. lq-text was developed with some more specific goals in mind, described in the following sections.
In the literature, the terms recall and precision are used to refer to the proportion of relevant matches retrieved and the proportion of retrieved matches that are relevant, respectively; the goal of lq-text is to have very high precision, and to give the user some control over the recall. These terms are defined more precisely in the literature [Clev66], [Salt88], and are not discussed further in this paper. The term accuracy is used loosely in this paper to refer to literal exactness of a match - for example, whether Ankle matches ankles as well as ankle. In an inaccurate system, Ankle might also match a totally dissimilar word such as yellow. The information that lq-text stores in the database enables it to achieve a high level of accuracy in searching for phrases.
This paper shows how some of the goals have been met, and indicates where work is still in progress on other goals.
All of the original design goals are still felt to be relevant. With continued improvements in price/performance ratios of disks, the offline storage goal may become less important, but the design philosophy is still very important for CD/ROM work.
This section gives a brief background to some of the main approaches to text retrieval.
In order to make the index smaller, however, the list of matches for each word is compressed, as described in detail in the Implementation section below.
The package is implemented as a C API in a number of separate libraries, which are in turn used by a number of separate client programs. The programs are typically combined in a pipeline, much in the manner of the probabilistic inverted index used by refer and hunt [Lesk78].
The lq-text package includes a set of input filters for reading documents into a canonical form suitable for the indexing program lqaddfile to process; a set of search programs; and programs that take search results and deliver the corresponding text. There are also wrappers so that users don't have to remember all the individual programs. The lq-text package has been successfully integrated into a number of other systems and products [Royd93], [Hutt94].
Three distinct kinds of index are used. The first uses ndbm, a dynamic hashing package [Knut81]. The second type of index is a fixed record size random-access file, read using lseek(2) and a cache. Finally, the third index contains linked lists of variable-sized blocks; the location of the head of each chain is stored in one of the other indexes, as detailed below. This third index is used to store the variable-sized data constituting the list of matches for each word-form. The combination of the three index schemes allows fast access and helps to minimise space overhead.
Two ndbm-clone packages are distributed with lq-text. One of these, sdbm, has been widely distributed and is very portable [Yigi89]. The other, db, is part of the 4.4BSD work at Berkeley, and is described in [Selt91]. A general discussion on implementing such packages was distributed in [Tore87]. See also ndbm(1).
Two ndbm databases are used: one maps file names into File Identifiers (FIDs), and the other maps natural-language words into Word IDentifiers (WIDs).
| Field | Example |
|---|---|
| location | /home/hermatech/cabochon/letters |
| name | tammuz.ar(june-14.Z) |
| title | Star Eyes watched the jellycrusts peel |
| size | 1352 bytes |
| last indexed | 12th Dec. 1991 |
The size and date fields shown in the table are used to prevent duplicate indexes of the same file, so that one can run lqaddfile repeatedly on all the files in a directory and add only the new files to the index (no attempt is made to detect duplicated files with differing names). In addition, the file size allows lq-text to make some optimisations to reduce the size of the index, such as reserving numerically smaller file identifiers for large files. The reasoning is that larger file are likely to contain more, and more varied, words. Since the file identifier has to be stored along with each occurrence of each word in the index, and since (as will be shown) lq-text works more efficiently with smaller numbers, this can be a significant improvement.
In fact, all of the above information except the document title is stored directly in the ndbm index. Using a multi-way trie would probably save space for the file locations, but the file index is rarely larger than 10% of the total index size. The DOCPATH configuration parameter and Unix environment variable supported by lq-text allow the file names to be stored as relative paths, which can save almost as much space as a trie would, and at the same time allows the user to move entire hierarchies of files after an index has been created. The document title is kept in a separate text file, since users are likely to want to update these independently of the main text.
For each unique word (that is, for each lemma), lq-text stores the following information:
| Field | Bytes |
|---|---|
| Word length | 1 |
| the Word itself | (wordlength) |
| Overflow Offset | 4 |
| No. of Occurrences | 4 |
| Flags | 1 |
| Total | 10 + word�length |
The word length and the word are stored only if the WordList feature is not disabled in the database configuration file. The Overflow Offset is the position in the data overflow file (described below) at which the data for this word begins. The remainder of the word index record is used to store the first few matches for this word. In many cases, it turns out that all of the matches fit in the word index, and the Overflow Offset is set to zero.
The flags are intended to be a bitwise `and' of all the flags in the per-word entries described below, but this is not currently implemented, and the space is not reserved. When implemented, this will let lq-text detect whether all occurrences of a word have a given property, such as starting with a capital letter. This information can then be used to recreate the correct word form in generating reports, and when searching the vocabulary.
| Field | Size in Bytes |
|---|---|
| FID (file identifier) | 4 |
| Block Number | 4 |
| Word In Block | 1 |
| Flags | 1 |
| Separation | 1 |
| Total | 11 |
Since, on average, English words are approximately four characters long, and allowing one character for a space between words, one might expect the index to be approximately double the size of the data from the per-match information alone. Many commercial text retrieval systems do as badly, or worse [Litt94].
In fact, the information is stored compressed. The matches are stored sorted first by FID and then by block within file, then by word in block. As a result, for all but the first match it is only necessary to store the difference from the previous FID. Furthermore, matches for a single FID are grouped together, so that it isn't necessary to repeat the FID each time. The informtion ends up being stored as follows:
[DELTA]FID (difference from previous File IDentifier)
Number of following matches using this FID
Block In File
Word In Block
Flags (if present)
Separation (if not 1)
[DELTA]Block In File
Word In Block
Flags (if different from previous)
Separation (if Flags and/or Seperation differ from previous)
Storing lower-valued numbers makes the use of a variable-byte representation particularly attractive. The representation used in lq-text is that the top bit is set on all but the last byte in a sequence representing a number. Another common representation is to mark the first byte with the number of bytes in the number, rather like the Class field of an Internet address, but this means that fewer bits are stored in the first byte, so that there are many more two-byte numbers.
The flags are stored only if they are different from the previous match's flags. This is indicated on the disk by setting the least significant bit in the Word In Block value; this bit is automatically bit-shifted away on retrieval. Further, the separation is only stored if the flags indicate that the value is greater than one (whether or not the flags were stored explicitly). The combination of delta-coding, variable-byte representation and optional fields reduces the size of the average match stored on disk from eleven to approximately three bytes. For large databases, the index size is about half the size of the data. Furthermore, since lq-text has enough information stored that it can match phrases accurately without looking at the original documents, it is reasonable to compress and archive (in the sense of ar(1)) the original files. When presenting results to the user, lq-text will fetch the files from such archives automatically.
The word is then looked up to see if it was in the common words file. If so, it is rejected and the next successfully read word will have the WPF_LASTWASCOMMON flag set. In addition, whenever the start of this word is more than one character beyond the start of the previous successfully read word - as in the case that a common word, or extra space or punctuation, was skipped - the next successfully read word will have the WPF_HASSTUFFBEFORE flag set, and the distance will be stored in the Separation byte shown in Table 3.
Common word look-up uses linear search in one of two sorted lists, depending on the first letter of the word. Using two lists doubled the speed of the code with very little change, but if more than 50 or so words are used, the common word search becomes a significant overhead; a future version of lq-text will address this.
After being accepted, the word is passed to the stemmer. Currently, the default compiled-in stemmer attempts to detect possessive forms, and to reduce plurals to the singular. For example, feet is stored as a match for foot, rather than in its own entry; there will be no entry for feet. When the stemmer decides a word was possessive, it removes the trailing apostrophe or 's, and sets the WPF_POSSESSIVE flag. When a plural is reduced to its singular, the WPF_WASPLURAL flag is set.
Other stemming strategies are possible. The most widespread is Porter's Algorithm, and this is discussed with examples in the references [Salt88], [Frak92]. Such an alternate stemmer can be specified in the configuration file. Porter's algorithm will conflate more terms, so that there are many fewer separate index entries. Since, however, the algorithm does not attempt etymological analysis, these conflations are often surprising.
The converted words are then mapped to a WID as described above, and stored in an in-memory symbol table. Whenever the symbol table is full, and also at the end of an index run, the pending entries are added to the index, appending to the linked-list chains in the data file. The ability to add to the data for an individual word at any time means that an lq-text index can be added to at any time.
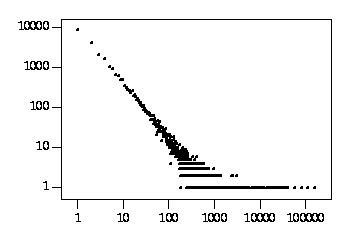
The figure shows the
vocabulary distribution graph
for the combined index to the King James Bible, the
New International Version, and the complete works
of Shakespeare, a total of some 15 megabytes of text.
The New International Version of the Bible is in modern English,
and the other two are in 16th Century English.
It can be seen from the graph that
a few words account for almost all of the data,
and almost all words occur fewer than ten times.
The frequency f of the nth most frequent word is usually given by
Zipf's Law,
f = k(n + m)s
where k, m and s are nearly constant for a given collection of documents [Zipf49], [Mand53]. As a result, the optimisation whereby lq-text packs the first half dozen or so matches into the end of the fixed-size record for that word, filling the space reserved for storing long words, is a significant saving. On the other hand, the delta encoding gives spectacular savings for those few very frequent words: `the' occurs over 50,000 times in the SunOS manual pages, for example; the delta coding and the compressed numbers reduce the storage requirements from 11 to just over three bytes, a saving of almost 400,000 bytes in the index. Although Zipf's Law is widely quoted in the literature, the author is not aware of any other text retrieval packages that are described as optimising for it in this way.lqword -A | awk '{print $6}' | sort -n
was sufficient to generate data for a grap(1) plot of
word frequencies shown in the graph, above.
It is also possible to pipe the output of lqword into the retrieval programs discussed below in order to see every occurrence of a given word.
The client then calls LQT_MakeMatches(), which uses the data structure to return a set of matches. A better than linear time algorithm, no worse than O(total number of matches) is used; this is outlined in Algorithm 1, and the data structure used is illustrated in Figure 2.
[1] For each word in the first phrase {
[2] for each subsequent word in the phrase {
[3] is there a word that continues the match rightward? {
Starting at current pointer, scan forward for
a match in the same file;
Continue, looking for a match in the same block,
or in an adjacent block;
Check that the flags are compatible
If no match found, go back to step [1]
Else, if we're looking at the last word {
Accept the match
} else {
continue at step [2]
}
}
}
}
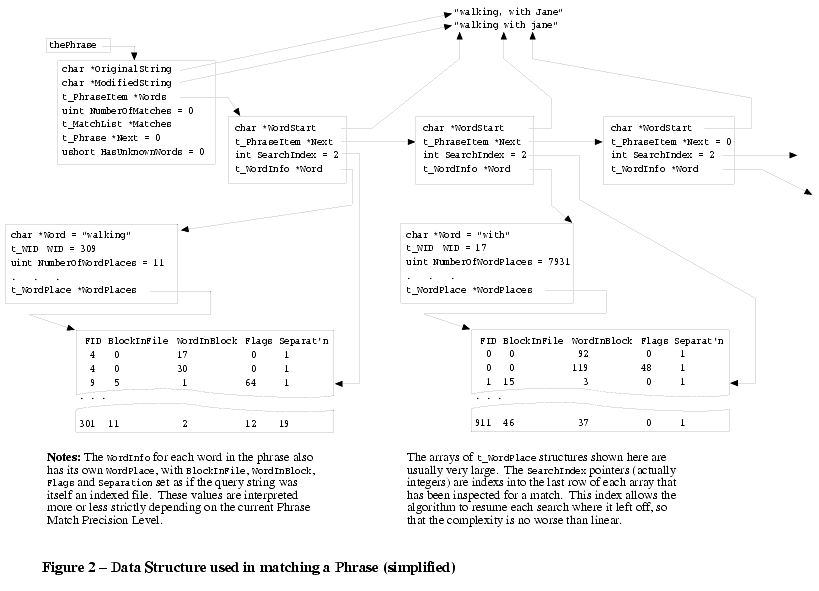
This appears O(nw) at first sight, if there are w words in the phrase each with w matches, but the search at step [3] resumes at the `current' pointer, the high-water mark reached for the previous word at step [1]. As a result, each match is inspected no more than once. For a phrase of three or more words, the matches for the last word of the phrase are inspected only if there is at least one two-word prefix of the phrase. As a consequence, the algorithm performs in better than linear time with respect to the total number of matches of all of the words in the phrase. In addition, although the data structure in the figure is shown with all of the information for each word already read from disk, the algorithm is actually somewhat lazy, and fetches only on demand.
Statistical ranking - for example, where documents containing the given phrases many times rank more highly than those containing the phrases only once - is also planned work. See [Salt88]. Statistical ranking and document similarity, where a whole document is taken as a query, should also take document length into account, however; this is an active research area [Harm93].
The initial implementation of lqrank used sed and fgrep. This was improved by Tom Christiansen to use perl, and then coped with larger results sets (fgrep has a limit), but was slower.
The current version is written in C. For ease of use, lqrank can take phrases directly, as well as lists of matches and files containing lists of matches.
The algorithms in lqrank are not unusual; the interested reader is referred to the actual code.
[1] Number of words in query phrase
[2] Block within file
[3] Word number within block
[4] File Number
[5] File Name and Location
(Items [4] and [5] are optional, but at least one must be present.)
In itself, this is often useful information, but the programs described below - lqkwic and lqshow - can return the corresponding parts of the actual documents.
See the Appendix for sample lqkwic output.
The original purpose of lq was to demonstrate the use of the various lq-text programs, but lq is widely used in its own right. A brief example of using lq to generate a keyword in context listing from the netnews news.answers newsgroup is shown in the Appendix.
At one point, lqaddfile was spending over 40% of its time in stat(2). It turned out that it was opening and closing an ndbm database for every word of input, which was suboptimal.
Now, most of the routines spend more than half of the time doing I/O, and no single function accounts for more than 10% of the total execution time.
The following searches were timed; since the results for the various forms of grep were always very similar for any given set of files, the grep timings are only given once for each collection of data.
The following small corpora were used:
| Index | egrep | ggrep | agrep | lq-text | ||
|---|---|---|---|---|---|---|
| [1] Not Found | [2] Common | [3] Unusual | ||||
| man pages | 41.5 | 37.1 | 45.9 | 1.8 | 0.0 | 0.3 |
| Bible | 60.2 | 55.5 | 67.7 | 1.8 | 1.2 | 0.1 |
| FAQs | 181.9 | 179.2 | 115.7 | 0.3 | 1.0 | 0.2 |
Index Size Creation Time Data Index real user sys man 12M 6.5M 267.4 124.9 64.5 Bible 15M 6.6M 351.3 136.6 51.0 FAQs 41M 20.5M 1598.8 851.9 375.8
The lq-text timings do not include the time to produce the text of the match, for example with lqkwic. However, running lq-kwic added less than one second of run�time for any except the very large queries, even when the data files were accessed over NFS.
The index overhead is approximately 50% of the size of the original data. This can be controlled to some extent using stop-words; the news.answers database used 79 stop-words, reducing the database by about 2 Megabytes. In addition, single-letter words were not indexed, although the presence of a single-letter word was stored in the per-word flags. The other databases used no stop words, and indexed words from 1 to 20 characters in length - the differences are because the FAQ index is accessed by a number of other users on our site.
An ad hoc test suite is included with the lq-text distribution, but this needs to be made more formal, and to be run automatically when the software is built.
The source for lq-text is available for anonymous ftp from ftp.cs.toronto.edu in /pub. Updates are announced on a mailing list, which you may join by sending lq-text-request at sq.com including your name and mail address. There is also a discussion group for new features and upcoming test releases, which you may ask to join by sending mail to lq-text-beta-request at sq.com explaining your interest.
PRIVATE void
MatchOnePhrase(Phrase)
char *Phrase;
{
t_Phrase *P;
unsigned long matchCount;
if (!Phrase || !*Phrase) {
/* ignore an empty phrase */
return;
}
if ((P = LQT_StringToPhrase(Phrase)) == (t_Phrase *) 0) {
/* not empty, but contained no plausible words */
return;
}
/* PrintAndRejectOneMatch() is a function that prints
* a single match. It is called for each match as soon as it is
* read from the disk. This means that results start appearing
* immediately, a huge benefit in a pipeline.
* The `Reject' is because it doesn't retain the match in the
* returned data structure.
*/
matchCount = LQT_MakeMatchesWhere(P, PrintAndRejectOneMatch);
/* finished. */
return;
}
This listing shows part of a session using lq, a shell-script that uses lq-text. The faq command invokes lq after setting up environment variables and options to use the news.answers database.
: sqrex!lee; faq Using database in /usr/spool/news/faq.db... | Type words or phrases to find, one per line, followed by a blank line. | Use control-D to quit. Type ? for more information. > text retrieval > Computer Science Technical Report Archive Sites == news/answers/17480 1:v.edu> comments: research reports on text retrieval and OCR orgcode: ISRI Interleaf FAQ -- Frequently Asked Questions for comp.text.interleaf == news/answers/17607 2:g with hypertext navigation and full-text retrieval. 1.2. What platform alt.cd-rom FAQ == news/answers/17643 3:and Mac. 56. Where can I find a full text retrieval engine for a CDROM I a 4:======== 56. Where can I find a full text retrieval engine for a CDROM I a 5: I am making? Here is a list of Full-Text Retrieval Engines from the CD-PU OPEN LOOK GUI FAQ 02/04: Sun OpenWindows DeskSet Questions == news/answers/18078 6:OOK/XView/mf-fonts FAQs;lq-text unix text retrieval who is my neighbour? OPEN LOOK GUI FAQ 04/04: List of programs with an OPEN LOOK UI == news/answers/18079 7: Description: Networked, distributed text-retrieval system. OLIT-based fr 8:OOK/XView/mf-fonts FAQs;lq-text unix text retrieval who is my neighbour? [comp.text.tex] Metafont: All fonts available in .mf format == news/answers/18080 9:OOK/XView/mf-fonts FAQs;lq-text unix text retrieval who is my neighbour? OPEN LOOK GUI FAQ 03/04: the XView Toolkit == news/answers/18082 10:OOK/XView/mf-fonts FAQs;lq-text unix text retrieval who is my neighbour? Catalog of free database systems == news/answers/18236 11:------------------ name: Liam Quin's text retrieval package (lq-text) vers 12: are bugs. description: lq-text is a text retrieval package. That means | Type words or phrases to find, one per line, followed by a blank line. | Use control-D to quit. Type ? for more information. > :less 9 (brings up the 9th match in a pager) > :help | Commands | | :help | Shows you this message. | :view [n,n1-n2,n...] | Use :view to see the text surrounding matches. | The number n is from the left-hand edge of the index; | :set maxhits explains ranges in more detail. | :page [n,n1-n2,n...] | Uses less -c (which you can set | in the $PAGER Unix environment variable) to show the files matched. | :less [n,n1-n2,n...] | The same as :page except that it starts on the line number | containing the match, firing up the pager separately on | each file. | :index [n,n1-n2,n...] | This shows the indexfor the phrases you've typed. | :files [n,n1-n2,n...] | This simply lists all of the files that were matched, | in ranked order. | :prefix prefix-string | Shows all of the words in the database that begin with that prefix, | together with the number of times they occur. | :grep egrep-pattern | Shows all of the words in the database that match that egrep pattern, | together with the number of times they occur (not the number of files | in which they appear, though). | :set option ... | Type :set to see more information about setting options. | :shell [command ...] | Use /home/sqrex/lee/bin/sun4os4/msh to run commands. | | Commands that take a list of matches (n,n1-n2,n...) | only work when you have generated a list of matches. If you don't give | any arguments, you get the whole list. | > :set | :set match [precise|heuristic|rough] | to set the phrase matching level, | currently heuristic matching (the default) | :set index | to see a Key Word In Context (KWIC) index of the matches | :set text | to browse the actual text that was matched | :set database directory | to use the database in the named directory. | Current value: /usr/spool/news/faq.db | :set rank [all|most|any] | all presents only documents containing all the phrases you typed; | most shows those first, and then documents with all but one of | the phrases, and so on. | any doesn't bother sorting the matches; this is the default, | because it's the fastest. | Currently: find documents containing all of the phrases | :set tags string | determine whether SGML tags are shown or hidden in the KWIK index | :set tagchar string | set the character used as a replacement for hidden SGML tags | :set maxhits n|all | show only the first n matches (currently 200) | :set prompt string | set the prompt for typing in phrases to string > ^C Interrupted, bye. : sqrex!lee;