Lessons From an XML Query-Qriven SVG+XHTML Web Site
XML, databases, XML Query, SVG, image search, WWW, XHTML, bare feet
Liam Quin
XML Activity Lead
W3C
Toronto
Ontari
Canada
liam@w3.NOSPAMPLEASEorg
http://www.holoweb.net/~liam/
Liam Quin has a background in typography and in computer science;
he is currently XML Activity Lead at the World Wide Web Consortium.
XML Query is a database query language for manipulating collections of
data presented as XML. It is as yet largely untested in the field,
although as the specification solidifies and implementations become more
common, the first flowers are starting to blossom, and the results are
promising for a full harvest. In this paper the author describes a web
site back end that uses XML Query to integrate a relational database,
RDF image descriptions and a geographical database to support searching
of a collection of royalty free images. The web site has a variety of
output formats including an SVG graphical mode.
The queries are sored in template files, so that they could be edited
easily. A library of XML Query functions is provided for the template
writer, both for ease of authoring and for long-tem stability.
Physical properties of the scanned images (file size, width, height and
so forth) are stored in a relational database; metadata about what the
images depict is stored in RDF; there is also an XML file describing the
proximity of geographical regions. This separation was done partly to
explore the integration possibilities of XML Query, and partly to help
ensure a clean map/terrain separation in the metadata.
The resulting search facility is in use, although currently with only
a few hundred images. Three user interfaces are provided, to attempt
to address differing user needs. Two of these are in (X)HTML, and one
in SVG allowing users to drag thumbnails around and to explore their
inter-relationships.
Galax was used as an XML Query engine because of its strong typing via
XML Schema, aiding development significantly. Queries are generated on
the fly based on the input options and templates, and a results cache
helps to reduce load on a busy system.
The paper discusses the architecture used, the development, and the
difficulties encountered, ranging from the technical (such as generating
random placement of objects using the purely functional XML Query
language) to the philosophical (such as separating the description of
representations such as actual image scans out from the objects depicted).
The work is unusual because it uses XML Query to tie together a range of
data sources all presented as XML, and in this shows how XML is solving
problems that a decade ago were major expenses in consulting projects.
The software was quick to develop, and shows clearly the benefits
of using XML as a communication format at all points of a system.
Future work may include an exploration of RDF representations of
inexact dates and time-lines (e.g., This castle was constructed in
approx. 1230 CE), further use of XML Schema to simplify queries and
increase robustness, extension of the SVG interface, and the use of full
text and updates to improve the searching and metadata.
1. Introduction
2. The Problem
3. Existing Architecture
4. First Steps: Data Mining
5. Searching these Sources with XML Query
6. Distant Relatives and Retrieving Relationals
7. Templates and a CGI Script for searching
7.1 Listing 1: Simple Template
8. Matching
8.1 Listing 2: Sample lq:findMatches() Function
9. Strong Typing
10. Generating Graphics
11. Architecture Revisited
12. Future Work
13. Conclusions
I wanted to experiment with XML Query, and since I already had
a Web site that was large enough for experiments, I decided to give
it a go. In particular, as W3C Alternate Team Contact to the W3C XML
Query Working Group, I wanted to use the language in something I cared
about, but on which no-one else depended, so that I'd get experience
with its strengths and weaknesses. Now that I've done that a little,
I want to share that experience.
The lessons children learn when they play in the sandpit stay
with them for the rest of their lives. Of course, sometimes all they
learn is that the strongest child likes to invade the other children's
sandpits. We hope, however, that they learn to cooperate one with
another, and to share what they discover.
In this paper I shall describe a template-based search
facility for a Web-based collection of historical images. It's not
mission-critical but, like the sandpit, it's a fairly constrained
environment with clear system boundaries. The search facility is in
production use today. In describing how I built this facility I shall
draw attention to the difficulties I encountered, and also to the
benefits of using XML Query.
Some of these benefits may be surprising.
For several years I have been scanning images from a number of
antiquarian books that I own. Some of these images are quite popular,
and as of March 2004 the Web site gets over 12,000 hits from over
2,000 distinct visitors each day. I spent some time studying the
ways people found the Web site, and how they interacted with it,
using the Apache “httpd” referrer log that told me, for example,
the search term someone had entered at a Web search engine such
as Google or Altvista, how far down the results my page appeared,
and where the user went after reaching my Web site.
See Figure 1 for an example.
Many people would encounter my Web site, clearly looking for a
specific image or sort of image, and come within a single link of
finding what they sought, and yet would not persist. I thought that
perhaps if I added a search facility, many of these people could more
easily explore my Web site and find images that interested them.
The searches were most often expressed in general terms, such as
pictures from old books or castles.
Sometimes they were specific
but matched by coincidence, and in these cases, unless I added new
images to my Web site that might be relevant to the topic, there was
no search facility that could help, since I didn't have what the user
presumably wanted. Sometimes people searched for specific places or
image features, however, and these are the users I felt most likely
to be able to help.
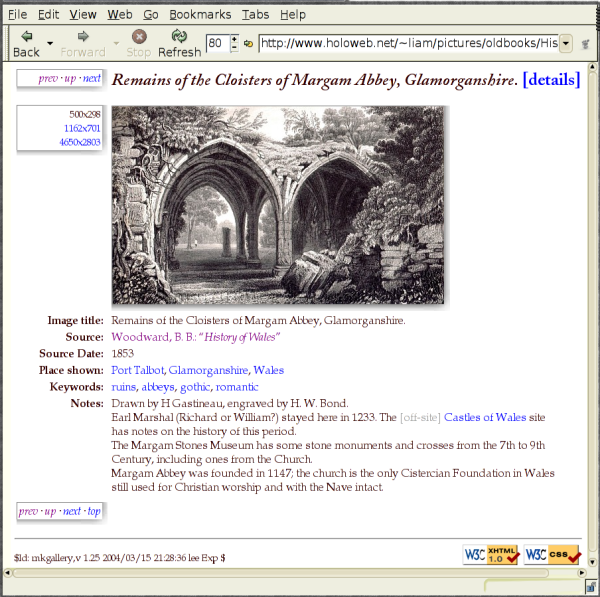
As an experiment, I tried adding a Web page of text about a place depicted in one of the images (Harlech Castle), and indeed this seemed to help people to find the image.
I should add that I already had a static HTML page for each image,
giving information about the location depicted, keywords, and notes or
a description.
One such page is shown in Figure 2 .
The text on these
pages was of course indexed (I made sure the pages were valid strict
XHTML, to minimise the chances that the search engines would fail to
understand them), and some of it also appears on an index page that I
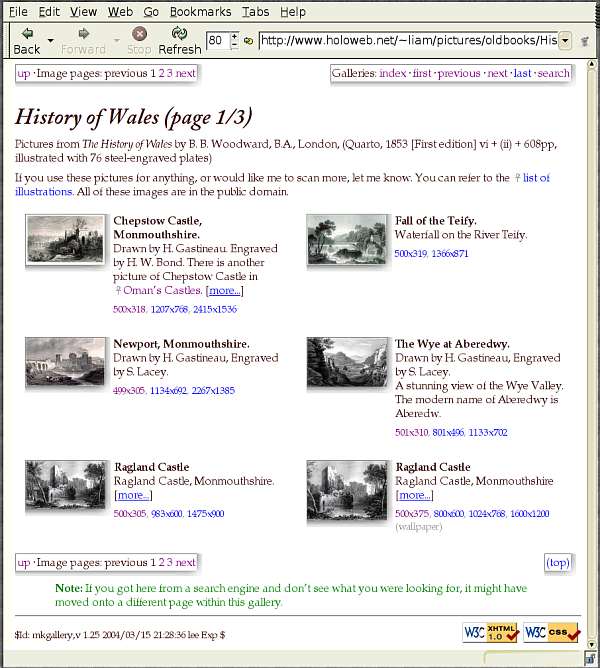
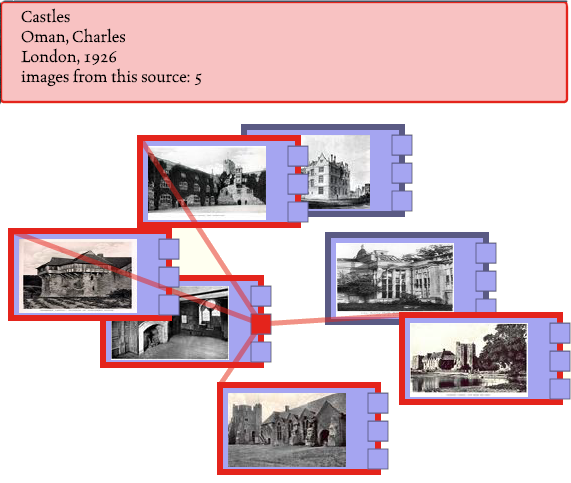
made for each source. A source here is an antiquarian book from which
images were taken;
Figure 3 shows one such index page, for some of the
engravings from Woodward’s “History of Wales” (1853).
The problem, then, was to make a search facility that would let
users find images based on keywords or on locations. It had to be
reasonably fast, but, since this Web site is something I do entirely in
my own spare time, it also had to be easy to develop. For the reasons
given above, I decided to see if I could use XML Query.
The existing Web site, as mentioned in the previous Section,
uses entirely static HTML files. These files were, however, generated
by a Perl script. I had (and still have) a separate directory for each
image source, and, within that directory, a descrptions file that
associated metadata with the image. For mostly historical reasons,
this file is not in XML - if the cobbler's children can go barefoot,
so can the W3C XML Activity Lead!
A Perl script (mkgallery) reads the descriptions file and generates
one or more index pages together with a directory containing HTML pages
for each image. It's relevant to the searching because I was able to
reuse the descriptions files, and also to retain these static HTML
pages. Static pages work well with Web search engines, and also are
efficient to serve to clients, an important factor as the Web site is
on a very old Pentium system that I share with my brother! Our sandpit
doesn't have much sand.
If people are going to run searches against something, I have to
know against what. So I started out by converting the description
files to XML, and mining them for information. There are, as I see
it, two kinds of information that were relevant to me. The first is
information about each image and what it depicts. The second is about
the actual scanned image itself: people often search for 1600x1200 (a
common computer screen resolution and hence the pixel size needed for a
screen background or wallpaper), or they might for other reasons want
only specific image sizes.
One should not, of course, mix logical and physical information.
Harlech Castle is not, by any useful sort of reckoning, 1600 pixels wide,
even if I might have an image of Harlech Castle that's 1600 pixels wide.
On the other hand, none of my images is older than a decade, even though
the engravings from which the scanned images were created are themselves
mostly well over 100 years old.
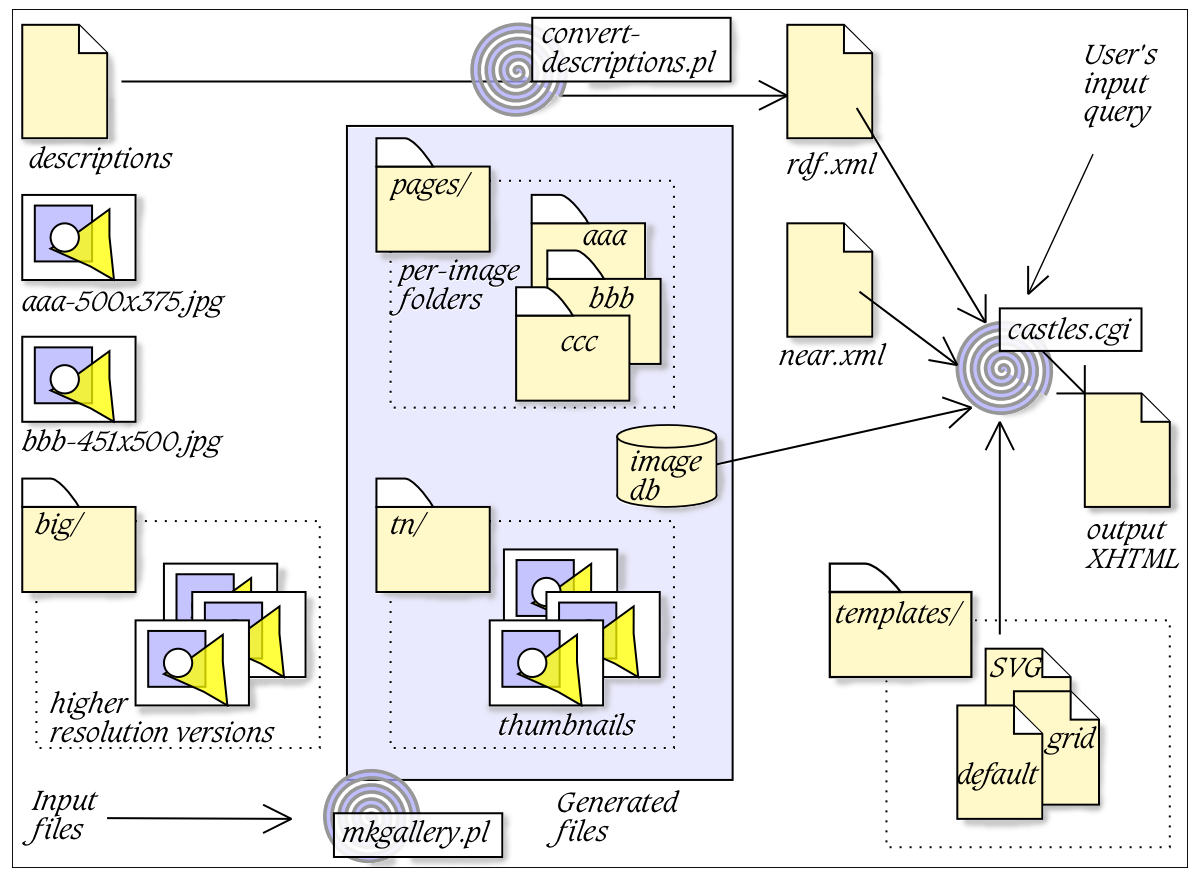
I stored the physical information in a relational database, and
put the logical information into an XML file, as RDF. In addition,
since I had recorded the name of the region in which each depicted
place exists (typically a British county such as Derbyshire or Devon),
I made an XML file that told me which counties were near to each other.
This file is not in RDF, although of course it could have been, and
may be in the future.
I ended up with the mess shown in Figure 4 .
Once I had made my three main indexes I of course wanted to search them. I started with the RDF, and wrote an XML Query expression to find all the images that depicted castles.
Before I proceed I should make a shame-faced admission: there is a hole in my sand-bucket. Or, to be more specific, my logical metadata was not at first anything at all like RDF. So the first queries I shall show are themselves not very RDF-like. Here is one to find all the castles:
for $image in doc(metadata.xml)/metadata/images/image
where $image/keywords/item/text() = castles
return $image/@id
|
Even without seeing a DTD (or one of those new-fangled XML Schema Documents we shall see more of shortly), you can probably work out what's happening here. The only subtle part is that most images have multiple keywords associated with them, so the test in the where clause is actually comparing a sequence with a string. In the grand old XPath and XSLT 1 tradition, this returns true if there is any member of the sequence that has the given string value. This process is called in the literature implicit existential quantification, as good a cause for a change of name by deed poll as I ever encountered.
For searching the dtabase of physical information, I had a problem: the database I was using, MySQL, didn't support XML Query. Luckily I was able to write a very short Perl script using the Perl DBI (you could easily use PHP instead, or some other language), the purpose of which was to connect to the datbase and dump the contents of it as XML.
If I had been using an XML Query implemenation with ODBC and SQL support, I would not have needed to do this. But the exciting thing here is that the Perl CGI script I wrote was entirely independent of the XML Query search code. All I needed was for the CGi script to return XML, and I could process it. I didn't need any database cod in my search script, and if I later obtain access to an XML Query implementation that connects directly to a relational database, I can simply discard that Perl DBI CGI script altogether. The script is under 80 lines long, and the bulk of it is simply this:
my $sth = $dbh->prepare("SELECT * FROM imageinfo");
$sth->execute();
my $NS = "http://www.example.org/imageinfo-1.0";
print "<ii:imageinfo xmlns:ii='${NS}'>\n";
while ($hr = $sth->fetchrow_hashref) {
print <ii:image>;
foreach my $key (keys %$hr) {
if (defined $$hr{$key} && $$hr{$key} ne "") {
print "<ii:$key>", $$hr{$key}, "</ii:$key>";
}
}
} |
I could now search the relational database (albeit inefficiently) as follows:
declare namespace ii = "http://example.org/imageinfo-1.0";
doc("http://localhost/imageinfo.cgi")/ii:imageinfo/ii:image[
ii:filename = "xxx.jpg"
] |
Since the CGI script returns XML, I can query it. Again I wish to emphasize that what's going over the wire is XML. Although I have shown some Perl, this was associated (in my mind at least) with the database, and not with the search code. In particular, there's no proprietary goop coming over the wire and then being converted by libraries I call or code I have to write, so-called middleware between components. These components plug together directly.
Typing XML Query expressions at a Unix command line is all very
well and good, but doesn't help users of my Web site. I wrote a short
CGI script in Perl that generates an XML Query function on the fly,
selects an XHTML file for use as a query, and passes the function and
the template to an XML Query processor. The results are marshalled
and sent back to the user, and also saved in a cache to save my poor
pentium's brains.
The function generated is called findMatches(),
and can be called by the query in the template. The template is an
XHTML file with embedded XML Query expressions; in addition to the
findMatches() function, a number of other functions are provided that
a writer of templates might choose to call.
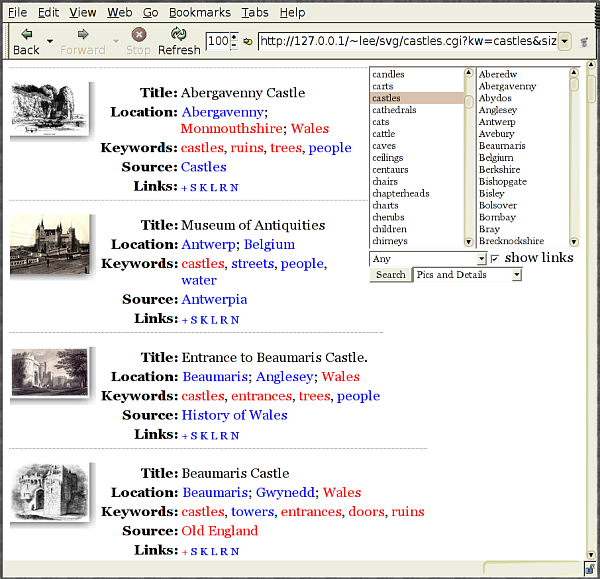
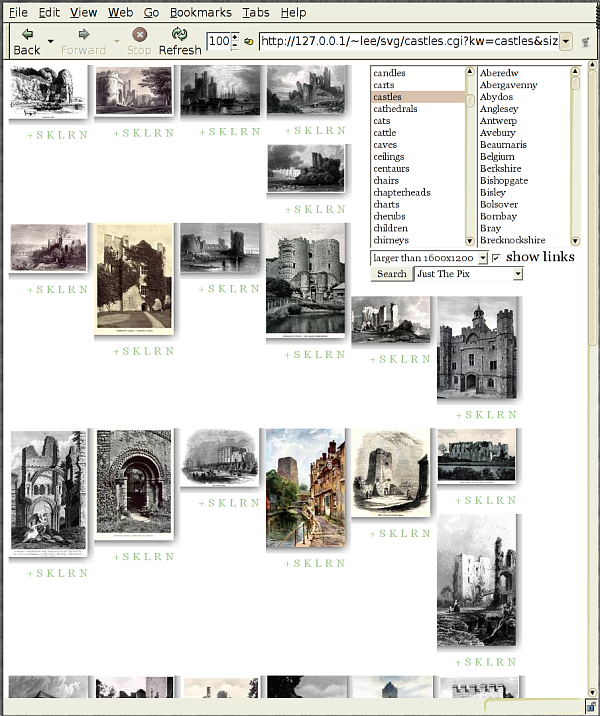
Figure 5 shows part of the output from the system
after the user searched for depictions of castles.
A simple template is shown in Listing 1;
this is not the actual template that produced the results in
Figure 5 , in the interests of brevity and clarity, but
rather an abbreviated template from which the principles of their
construction will, I hope, be clear.
The functions in the namespace bound to the lq prefix in the
example template are provided by a function library the author wrote;
these simplify the task of writing templates, and also help to shield the
template writer from changes in the underlying representation of
the metadata being searched.
<html>
<head>
<title>Search Results</title>
</head>
<body>
<h1>Search Results</h1>
{
for $image in lq:findMatches()
return
<table>
<tr>
<th>Image:</th>
<td><img src={lq:URI($image)}/></td>
</tr>
<tr>
<th>Title:</th>
<td>{lq:title($image)}</td>
</tr>
</table>
}
</body>
</html> |
The template in Listing 1 constructs a table for each image in the results. If there are no results there will be no tables.
You can see at once that the template is very straight-forward. Furthermore, it is itself a valid XML Query expression, once combined with the necessary declarations that the CGI script provides. A first round of this entire system was working in well under an hour.
The functions lq:URI() and lq:title() are provided by a function library (an XML Query module) imported automatically by the CGI script; lq:findMatches() is constructed on the fly by the CGI script.
Notice how the exact representation of an image is not reflected directly in the template. It could be, of course: I could write concat($TOP, "/", $image/basefilename) instead of URI($image) and the effect might be the same. But the use of functions has meant that when I changed the metadata format to be closer to RDF, I did not need to make large change to the templates I had written.
Another benefit of using functions is extra type checking, and I shall return this topic later. First, let us examine in more detail how the findMatches function might work.
The CGI script, castles.cgi, constructs a Query Prolog that declares a number of functions, some variables and namespaces, and that can also import a function library. The Query Prolog continues at the start of the template, so that a template can define additional functions or namespaces as needed. In practice I have only needed this for testing and development, or for a particularly complex template that generates the results in graphical (SVG) form, which I shall describe in its own Section later.
Listing 2 shows a sample findMatches() function generated for the case in which the user has supplied some keywords and a location, and also requested that images by exactly 1600x1200 pixels in size.
declare function lq:findMatches()
as element (image, image)*
{
for $i in $metadata/metadata/image[kw/item = $keywordlist/item]
[ location/item = $locationlist/item ]
where lq:isNearto($i/location, "Bedfordshire")
and lq:checkSize($i, "equal", 1600, 1200)
order by $i/location
return $i
} |
This is close to the most complex findMatches() ever gets;
it demonstrates a mixture of using the XPath child axis, implicit existential quantification for matching keywords and locations, and a where clause to filter the results based on more complex expressions. Those images that make it past the node tests and the where clause are sorted by location, and the return value of the function, as per its declaration is zero or more elements of name image and that have a schema type of image.
In the interests of full disclosure I shall mention that although I started out using an open source XML Query implementation with W3C XML Schema support (Galax), at the time of writing (March 2004) I am using Saxon and Qizx/open, neither of which currently has Schema support. I shall talk more about this in the next Section; if you try this query yourself, though, you'll need to use element (*)* instead, unless you have a Schema.
I originally used function calls to test all of the possible predicates, but quickly discovered that Galax was too slow at implementing function call, and was not then optimizing the function calls very well. As with any query system, you can always find things that are optimized well and things that are optimized badly, and I got a noticeable speedup by using the XPath predicates (in square brackets) instead of function calls in the where clause.
Having the CGI script create the findMatches() function instead of the template author means that such performance issues can be solved once for all templates; it also means that the template author is insulated from changes to the metadata structure, and, more interestingly, that I could easily add new ways of searching without changing any templates at all.
The ease of adding new templates encouraged me to experiment with
layout; Figure 6 shows results presented using
a grid template.
When I was developing the functions and templates, I found the Schema support of Galax very useful: it would often tell me I was calling a function with the wrong sort of argument, for example. It was also a lot of work, to write a Schema and test it, but this in turn led to me finding errors in my data. and fixing them.
I am very much looking forward to using the Schema support again, either if I go back to Galax (when it implements a more recent version of the XML Query language) or in Saxon when available, or maybe some other engine.
It would also be useful to experiment with software such as XQEngine, an open source XML Query implementation that builds indexes of multiple documents, and then to put my RDF back into separate files. The Schema support may well help an indexing engine to make efficient indexes, but that remins to be seen.
There is no doubt that XML Query is enough like a programming language that it benefits very greatly from extra compile-time error checking. Until there are more books and tutorials readily available, the syntax of function call and parameter passing in XML Query may frustrate beginning users, although I don't see a solution other than education: the same could be said of most other programming languages.
By far the most complex template I have written is one whose
results are actually an SVG document. This turned out to be very
interesting. Unfortunately, the only SVG implementation I had
available that supported ECMAScript/JavaScript, needed for drag and
drop with SVG, was one that did not report syntax errors in the input.
It also did not support setting the text of the browser status bar,
nor popping up an alert box.
I wrote a JavaScript function that changed the
colour of a rectangle in the image, and called it frequently in the
script. I could then monitor the progress of my JavaScript functions
by checking the colour of the rectangle. It still took several days to
get drag and drop working. I found an example, but it was too complex to integrate with what I was doing. I subsequently discovered that one is
supposed to reference the example code externally in some unspecified
fashion, but in the end the code I wrote works fine as long as you don't
use the SVG viewer's zoom function. My main interest here was
XML Query and exploring interfaces, not SVG.
I used the Linux sodipodi graphics editor to create a sample SVG diagram, and then deconstructed the resulting XML document into a template. This part was not at all painful. A newer version of sodipodi called
Inkscape is much more polished and highly recommended by the
author.
Figure 7 shows sample output from the SVG template;
the figure is taken from a screenshot of a Web browser.
Users can drag the images about; they appear in a randomly
shuffled pile originally. This was difficult to implement
because it isn't
really possible to write a good random number generator in XQuery.
The problems are twofold. First, a function with no arguments will
always return the same value in a declarative language, unless it
refers to some external value, or to part of the Query Context such
as the current time. Second, there's no way to initialize the random
number generator except with the current time in seconds, which has
poor granularity. One can write a function random(n) which
recursively computes the nth random number, if one is very
patient waiting for results. In practice one might use a call to an
external Java or C function for this purpose.
In the end, I pre-generated the random numbers as x and y
attributes on each image, so that any given image always appears in
the same position. It's sucky, but it's good enough in practice.
Another approach would be to use JavaScript to move the images
around, but I wanted the default view to work in SVG viewers
that did not support JavaScript, even if a shuffled pile of
thumbnails wasn't very useful to them. Perhaps that was
afoolishness on my part.
I'd have liked to have provided a way for users to enter new
search data in the SVG, but I didn't get XForms working in the SVG
plugin I was using, and didn't want to start writing user interface
components in an environment without scripting and in which even a
few hundred graphics elements could bring my 650MHz laptop to its
knees.
The SVG representation is the least successful part of the
Web interface, because of problems with the deployment of SVG.
Perhaps it's an area where Linux lags, but I've found that browser
crashes are common enough that I decided not to make the SVG interface
available by default. Microsoft Windows users have also reported
crashes to me.
Recent builds of Mozilla have some native SVG support
enabled, and I'm hoping to be able to revisit the use of SVG on my
Web site over the next year or two.
At this point I have a CGI script that reads the result of a user filling in an HTML search form, checks that the values are plausible, creates an XML Query function to process these values and get a list of images, selects a template (also depending on form values), fires the template off to Galax, Saxon or Qizx/open, and sends the results to the user, at the same time keeping a copy in a cache to expedite repeat searches, whether by the same user or a different one.
I added the cache because, on my 650MHz laptop, a typical query was taking around 16 seconds; on the target250MHz Pentium server it was considerably longer.
This turned out to be a case of premature optimization: after studying some of the templates, I found I was calling findMatches() twice for each query. Fixing that got me down to about 12 seconds. A switch from the old version of Galax to Saxon, complete with removing Schema information, got it down to 6 seconds or so. Some more rewriting of the query and removing a lot of unused or duplicated information from my XML metadats file got it down to under five seconds. Finally, switching from Saxon to Qizx/open got the time down to approximately two seconds, an eight-fold speedup over the first version.
Since two seconds on my laptop translates to between six and ten seconds on my server, the cache is still needed, but much less than I had thought.
Since others have asked me if they can use my RDF data,
one of the things I've been working on is making my metadata comform
to the latest RDF specification more precisely.
I wrote code to generate an RSS feed, but was disappointed
that RSS viewers won't show my image thumbnails.
There seems little point in generating an RSS feed for a collection
of images if people won't be able to see the images.
I am hoping Atom will help with this issue, but have not yet checked.
It's fairly clear to me that the search facility could do
with full-text searching over the descriptions and captions.
Although I have written my own text retrieval package,
lq-text, first released in 1989,
I am waiting for the XML Query Working Group to publish a public
draft of the specification for text searching in XQuery.
I will then see if there are open source impleemntations,
or perhaps whether I can contribute code to an implementation.
I'd really like to add searching by date, but this is
very tricky. Apart from questions like representing approximage
spans time in RDF, one also has the problem of analyzing the images.
Consider a castle built in the 13th century, but on a site with
some Roman remains, perhaps including a Roman bridge. The castle
was modified heafily in the 14th century with the addition of
a chapel enclosed in a cloistered courtyard. In the 16th century
the chapel was converted to a manor house, complete with half-timbered
walls and a new roof, and in the 19th century the main castle
was used briefly as a factory, and gained a large tall chimney.
A picture showing several parts of such a castle might
reasonably turn up in the result set of a search for 13th century castles,
or for 14th century chapels, or 16th century manor houses. If the
chapel is not visible in the picture, but the Roman arch is clearly
shown, however, the results should presumably be different.
Should the picture show up for an image search of 15th century
castles? The building depicted was in use as a castle at that time,
but was not built then. Rather, the site
was more or less continuously modified over a span of perhaps two
thousand years.
In the face of such difficulties, I decided that I couldn't
really see what sort of image search would actually be useful.
A later analysis of the httpd server log, however, indicates
that people often search for architectural periods by name, such
a Jacobean or Tudor, so that associating those keywords
with an image solves the problem for the simplest cases.
Finally, I should mention that I am planning to add some
more links to books that visitors can purchase. I already have
links to let people buy modern reprints of the books I am scanning,
or to search antiquarian bookshops for copies of the originals,
and want to experiment with adding more links to related resources.
Who knows, maybe I shall get enough income from this to support
buying a much-needed new scanner, or more books.
With the exception of the cache (which is still a very simple piece of code), the entire search.cgi script is some 600 lines long, including the XML Query function library I wrote.
The templates are independent of each other, and are straight forward to maintain and understand (apart from the SVG one!).
The entire system is fairly easy to describe.
Ten years ago, this Web search facility would either have been a significant coding effort or used expensive proprietary middleware to connect databases together.
Five years ago I might have written custom C, Perl or Java code to handle the same thing, with the difficulty of having to manage the database connection, parse the metadata myself, and, more importantly, the inability to do the equivalent of a join over multiple databases.
Today, despite some minor difficulties, I quickly got a system working that is acceptably fast (although a few more hours would probably make it faster), that has acceptable functionality, and that used only open source technology and open, public specifications.
The Schema-based type system helped me to make the queries robust, so that I can deploy this system on what, for a personal Web site, is a moderately busy server, without having to baby-sit it all the time. And a clear strength of XML Query is its ability to combine XML from multiple souces into a single result.
As XML Query implementations become more sophisticated, I will most likely benefit by getting performance gains, and by being able to do fast searches over multiple indexed XML documents I'll no longer need to aggregate my RDF metadata.
On the evidence I have so far, I can surmise that integrating the features described above under Future Work will also be straight forward, because of the principle of XML Everywhere. I can also surmise that the reason there's so much interest in XML Query is that other people have worked these things out too, and are looking forward to enjoying a massive leap forward in data integration.
Let's leap out of the sandpit!
XHTML rendition created by
gcapaper Web Publisher v2.1,
©
2001-3 Schema Software Inc.